大模型中的token
-
token是什么?
-
大模型训练、推理本仍然是数值计算,文本通过分词、转换得到的数字即为token,不同模型采用不同词表得到的token不同。例如
算法工程师在gpt3模型中对应的token是[163, 106, 245, 37345, 243, 32432, 98, 163, 101, 233, 30585, 230] -
openai计费单位,按照输入token,输出token数量计算费用。 注意 input token 和 output token价格一般不同。openai计费价格,千帆大模型平台价格
-
-
token是怎么计算的?
通过openai提供的在线工具测试英文、中文 token结果如下:
-
英文
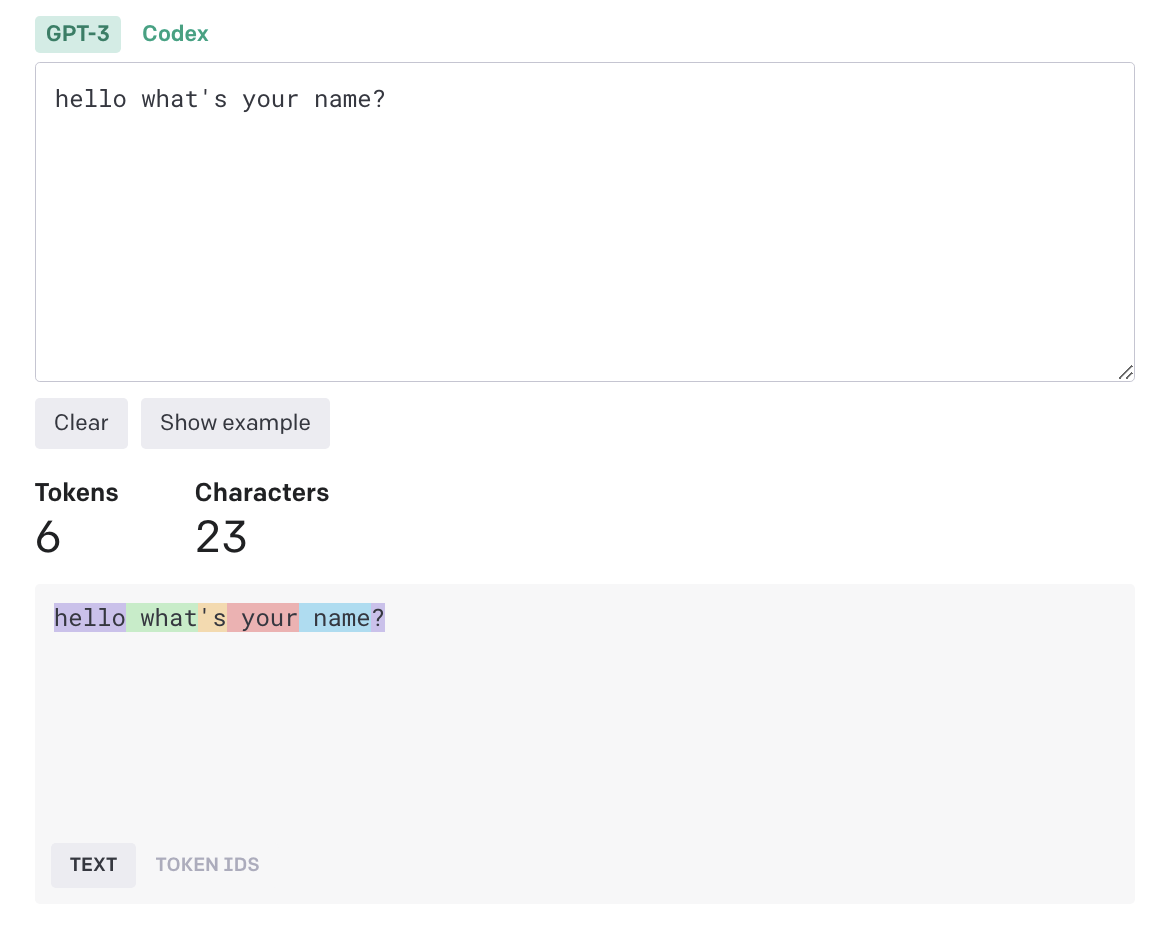
TOKEN IDS [31373, 644, 338, 534, 1438, 30]openai给出的经验法则是,对于普通英文文本,一个token通常对应约4个字符的文本。这大约相当于一个单词的3/4(因此100个token~=75个单词)。
-
中文
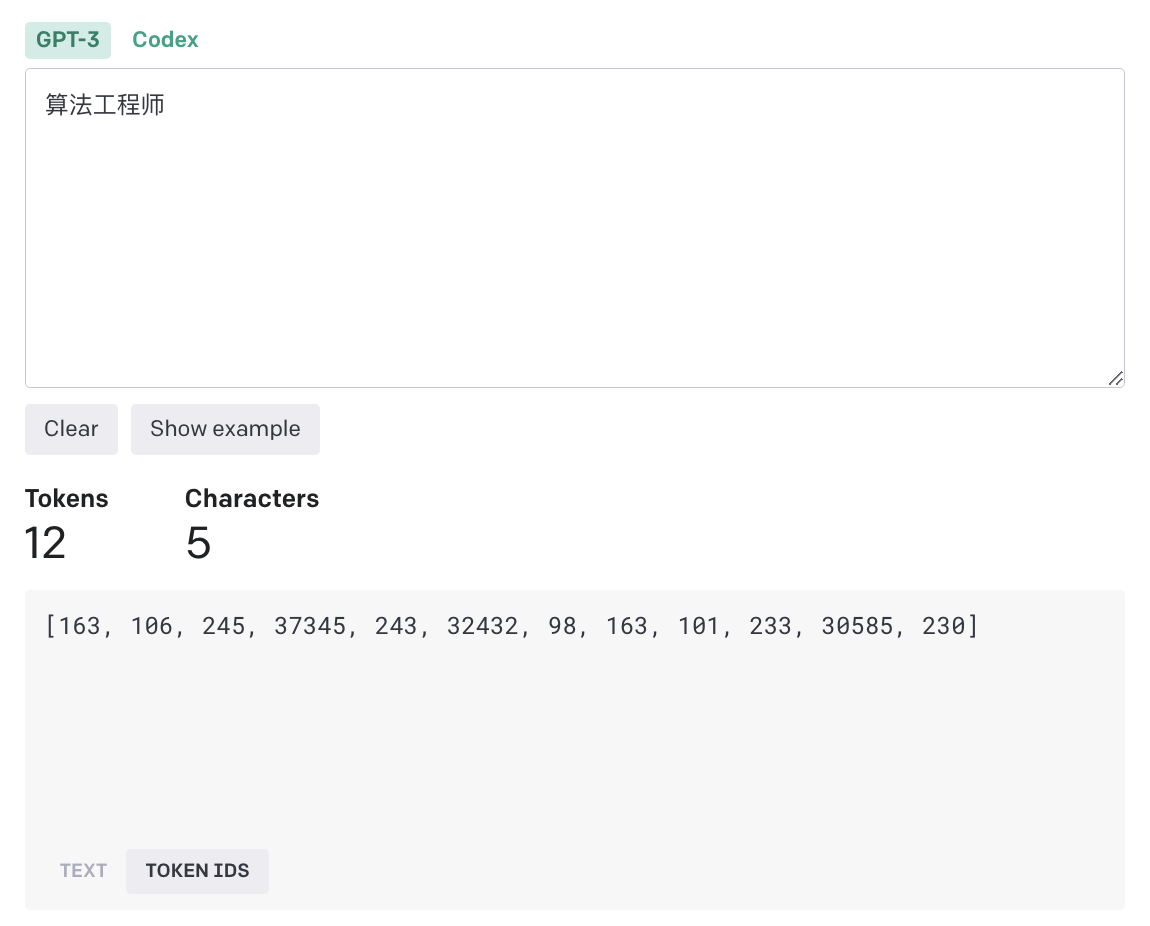
中文分词一个汉字可能对应多个token。
-
tiktoken
tiktoken是openai开源的token工具,
1)生成
算法工程师token id list。2)对每一个token还原可以得到token id代表的字节,例如:
163代表b'\xe7'。对比算法工程师utf-8 字节,可以发现与上述token id转换得到的字节一致。import tiktoken text = "算法工程师" enc = tiktoken.encoding_for_model("text-davinci-003") token_list = enc.encode(text) print("token_list", token_list) # [163, 106, 245, 37345, 243, 32432, 98, 163, 101, 233, 30585, 230] for x in token_list: print(x, enc.decode_bytes([x])) # 163 b'\xe7' # 106 b'\xae' # 245 b'\x97' # 37345 b'\xe6\xb3' # 243 b'\x95' # 32432 b'\xe5\xb7' # 98 b'\xa5' # 163 b'\xe7' # 101 b'\xa8' # 233 b'\x8b' # 30585 b'\xe5\xb8' # 230 b'\x88' # ... print("text utf-8 bytes", bytes(text.encode('utf-8'))) # text utf-8 bytes b'\xe7\xae\x97\xe6\xb3\x95\xe5\xb7\xa5\xe7\xa8\x8b\xe5\xb8\x88'通过上述实验可以token ids生产流程,字符串转换为utf-8编码,根据预先专备好的词表逐个匹配转换为 token id,具体过程如下:
词表
# 163 b'\xe7' # 106 b'\xae' # 245 b'\x97' # 37345 b'\xe6\xb3' # 243 b'\x95' # 32432 b'\xe5\xb7' # 98 b'\xa5' # 163 b'\xe7' # 101 b'\xa8' # 233 b'\x8b' # 30585 b'\xe5\xb8' # 230 b'\x88'1)算法工程师 2)b'xe7\xae\×97\xe6\xb3\×95\xe5\xb7\xa5\xe7\xa8\x8b\xe5\xb8\×88' 3)查词表 例 \xe7 => 163 1) token ids [163, 106, 245, 37345, 243, 32432, 98, 163, 101, 233, 30585, 230] -
openai不同模型token对比
https://github.com/openai/tiktoken/blob/main/tiktoken/model.py
gpt-4、gpt-3.5、embeddings用同一个词表cl100k_base;除gpt2、text-davinci-edit-* 其他用同一个词表 r50k_base。
MODEL_TO_ENCODING: dict[str, str] = { # chat "gpt-4": "cl100k_base", "gpt-3.5-turbo": "cl100k_base", "gpt-35-turbo": "cl100k_base", # Azure deployment name # text "text-davinci-003": "p50k_base", "text-davinci-002": "p50k_base", "text-davinci-001": "r50k_base", "text-curie-001": "r50k_base", "text-babbage-001": "r50k_base", "text-ada-001": "r50k_base", "davinci": "r50k_base", "curie": "r50k_base", "babbage": "r50k_base", "ada": "r50k_base", # code "code-davinci-002": "p50k_base", "code-davinci-001": "p50k_base", "code-cushman-002": "p50k_base", "code-cushman-001": "p50k_base", "davinci-codex": "p50k_base", "cushman-codex": "p50k_base", # edit "text-davinci-edit-001": "p50k_edit", "code-davinci-edit-001": "p50k_edit", # embeddings "text-embedding-ada-002": "cl100k_base", # old embeddings "text-similarity-davinci-001": "r50k_base", "text-similarity-curie-001": "r50k_base", "text-similarity-babbage-001": "r50k_base", "text-similarity-ada-001": "r50k_base", "text-search-davinci-doc-001": "r50k_base", "text-search-curie-doc-001": "r50k_base", "text-search-babbage-doc-001": "r50k_base", "text-search-ada-doc-001": "r50k_base", "code-search-babbage-code-001": "r50k_base", "code-search-ada-code-001": "r50k_base", # open source "gpt2": "gpt2", }不同词表token数量差别很大,例如
算法工程师使用cl100k_base消耗6个token,但是使用p50k_base消耗12个token。import tiktoken text = "算法工程师" enc_1 = tiktoken.encoding_for_model("gpt-4") token_list_1 = enc_1.encode(text) print("token_list_cl100k_base", len(token_list_1), token_list_1) enc_2 = tiktoken.encoding_for_model("text-davinci-003") token_list_2 = enc_2.encode(text) print("token_list_p50k_base", len(token_list_2), token_list_2) # token_list_cl100k_base 6 [70203, 25333, 49792, 39607, 13821, 230] # token_list_p50k_base 12 [163, 106, 245, 37345, 243, 32432, 98, 163, 101, 233, 30585, 230]
-
-
不同词表是怎么得到的?(cl100k_base、p50k_base、…)
-
根据tiktoken openai采用
BPE算法生成不同词表(Byte pair encoding) -
关于
BPE算法
-
-
参考资料