开源LLM
LLMs
LLaMA、GPT、Transformer
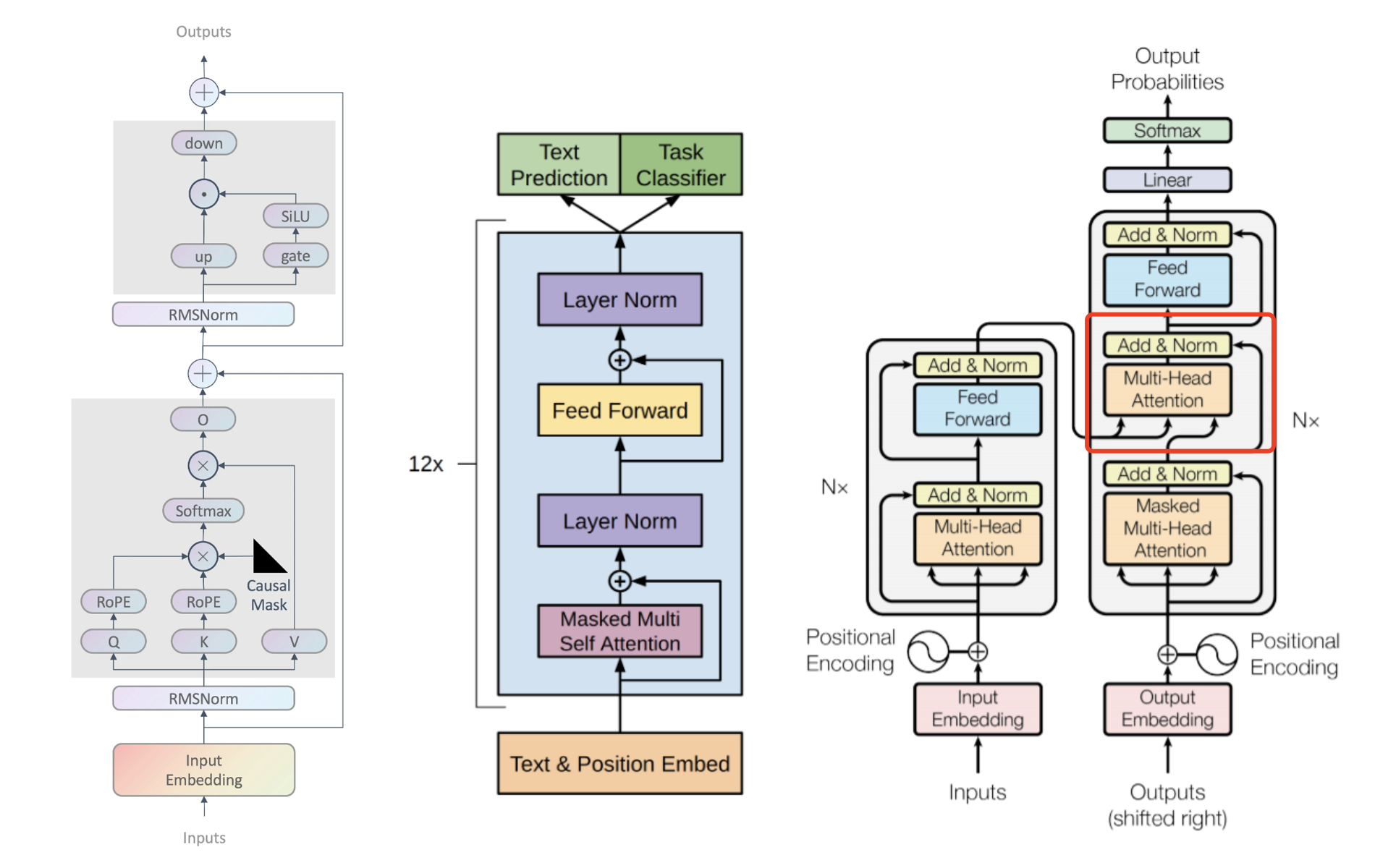
1)我们经常说GPT是transformer右侧部分,其实GPT不包含transformer右侧中间的Multi-Head Attention模块。
2)LLaMA在GPT基础上对多个组件优化。
支持中英文开源大模型
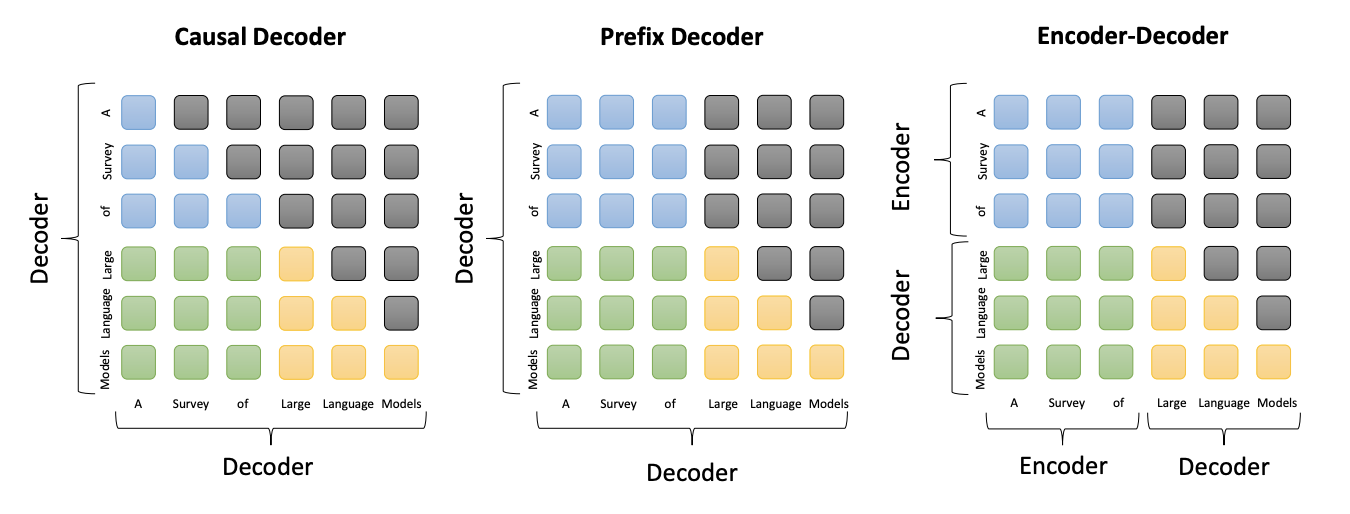
三种主流架构的注意力模式比较。
-
蓝色: 前缀 token 之间的注意力
-
绿色: 前缀 token 和目标 token 之间的注意力
-
黄色: 目标 token 之间的注意力
-
灰色: 掩码注意力
-
Causal Decoder //
单向注意力1)LLaMA
-
1.1 LLaMA 从零训练:Baichuan-7B/13B(百川智能)、Qwen-7B(阿里云)
-
1.2 LLaMA 增量微调:BELLE-7B/13B(链家)
2)GPT、ChatGPT、BLOOM
-
-
Prefix Decoder //
Encoder双向注意力、Decoder单向注意力、Encoder&Decoder共享参数1)ChatGLM-6B、ChatGLM2-6B(清华、智谱)
-
Encoder-Decoder //
Encoder双向注意力、Decoder单向注意力1) Flan-T5、Transformer
多模型对比
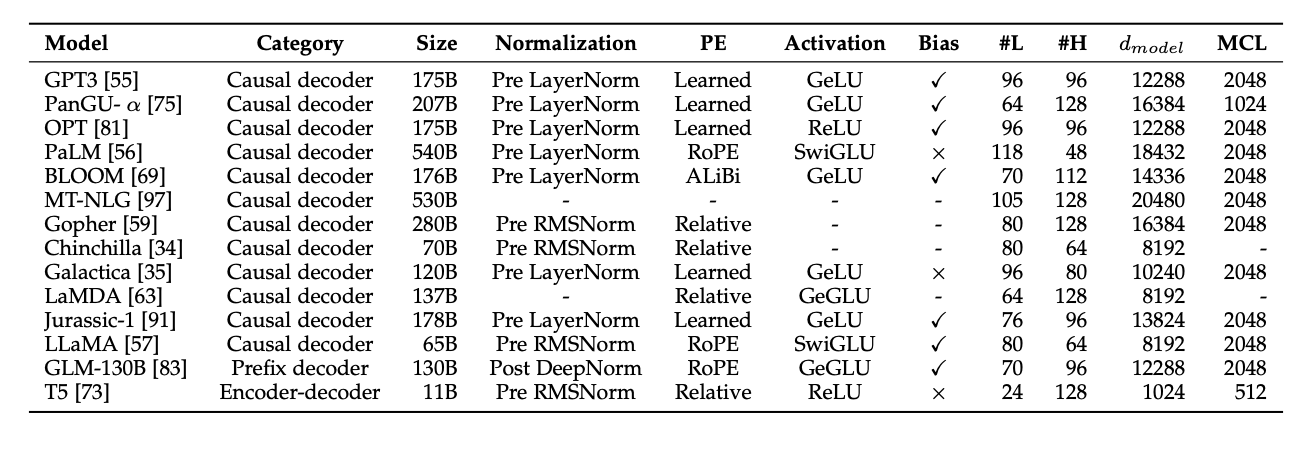
组件优化
PE(位置编码)
Learned、Relative、RoPE、ALiBi
Activation(激活函数)
SwiGLU、ReLU、GeLU、GeGLU
Normalization(归一化方法)
Pre RMSNorm、Pre LayerNorm、Post LayerNorm
Attention
Full attention、Sparse attention、Multi-query attention、FlashAttention