token是什么?
大模型训练、推理本仍然是数值计算,文本通过分词、转换得到的数字即为token,不同模型采用不同词表得到的token不同。例如 算法工程师 在gpt3模型中对应的token是 [163, 106, 245, 37345, 243, 32432, 98, 163, 101, 233, 30585, 230]
openai计费单位,按照输入token,输出token数量计算费用。 注意 input token 和 output token价格一般不同。openai计费价格,千帆大模型平台价格
token是怎么计算的?
通过openai提供的在线工具测试英文、中文 token结果如下:
英文
TOKEN IDS [31373, 644, 338, 534, 1438, 30] openai给出的经验法则是,对于普通英文文本,一个token通常对应约4个字符的文本。这大约相当于一个单词的3/4(因此100个token~=75个单词)。
中文
中文分词一个汉字可能对应多个token。
tiktoken
tiktoken是openai开源的token工具,
1)生成 算法工程师 token id list。
2)对每一个token还原可以得到token id代表的字节,例如:163 代表 b'\xe7'。对比算法工程师 utf-8 字节,可以发现与上述token id转换得到的字节一致。
import tiktoken text = "算法工程师" enc = tiktoken.
LLMs LLaMA、GPT、Transformer 1)我们经常说GPT是transformer右侧部分,其实GPT不包含transformer右侧中间的Multi-Head Attention模块。
2)LLaMA在GPT基础上对多个组件优化。
https://dugas.ch/artificial_curiosity/GPT_architecture.html
https://zhuanlan.zhihu.com/p/636784644
支持中英文开源大模型 三种主流架构的注意力模式比较。
蓝色: 前缀 token 之间的注意力
绿色: 前缀 token 和目标 token 之间的注意力
黄色: 目标 token 之间的注意力
灰色: 掩码注意力
Causal Decoder // 单向注意力
1)LLaMA
1.1 LLaMA 从零训练:Baichuan-7B/13B(百川智能)、Qwen-7B(阿里云)
1.2 LLaMA 增量微调:BELLE-7B/13B(链家)
2)GPT、ChatGPT、BLOOM
Prefix Decoder // Encoder双向注意力、Decoder单向注意力、Encoder&Decoder共享参数
1)ChatGLM-6B、ChatGLM2-6B(清华、智谱)
Encoder-Decoder // Encoder双向注意力、Decoder单向注意力
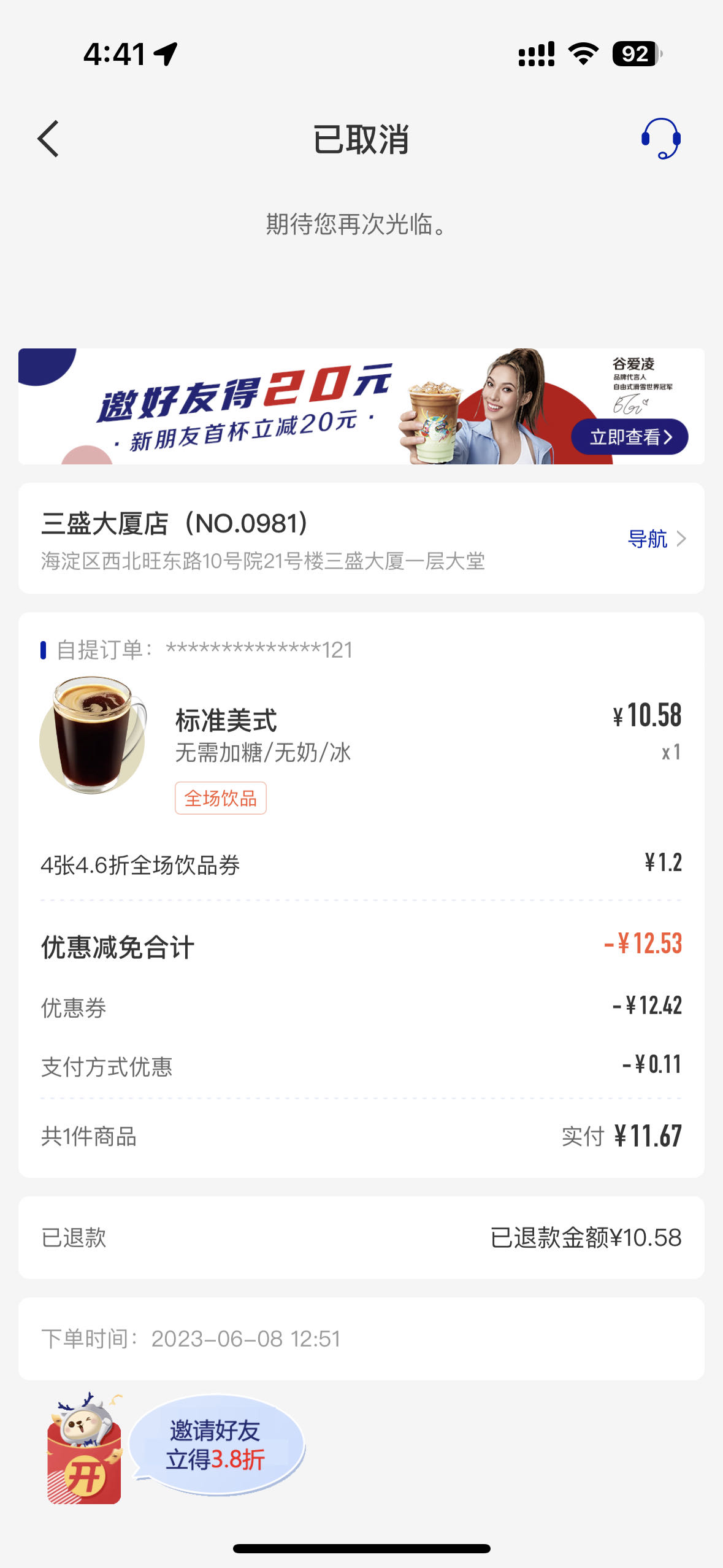
Q: app付款后退款你会检查退款金额吗?
A: 大部分时间不会,今天无意瞟了一眼发现了问题,对不上!
LLM Embedding ChatGLM ChatGLM获取Embedding向量
inputs = tokenizer([text], return_tensors="pt").to(device) resp = model.transformer(**inputs, output_hidden_states=True) y = resp.last_hidden_state y_mean = torch.mean(y, dim=0, keepdim=True) y_mean = y_mean.cpu().detach().numpy() print(y_mean.shape) > [1, 4096]
Common tools shell kill through name ps aux | grep "xxx.py"|grep -v grep|awk '{print $2}'|xargs kill -9 python pip tsinghua source pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy git clone LLM git lfs install git lfs clone <repo_URL> # breakpoint continuation git lfs fetch --all --resume <repo_URL> # clone without large files git lfs clone --skip-smudge <repo_URL> regex https://regex101.com/ ping https://17ce.
目信(SeeChat)
目信(SeeChat):目之所及的通讯。(在此之前亦称icebreak)
《842》 是考研时写的博客,记录了199x-2016年东北大学842专业课(C语言、数据结构)部分代码,由于时间有限并没有完整的题目,欢迎PR补充。
我的考研路 在图书馆回顾了考研历程,分准备考研、复习考研、考研调剂等阶段。
东北大学842考研
Motivation
如何开发以下需求?
-
业务 (Models、Prompt)
- 多模型(gpt-3.5, gpt-4, chatglm-6b, chatglm-6b-ft)
- 多业务(运营push、个性化push、weibo地域、商业评论、新闻评论……)
- 不同业务 X 不同模型 = 不同prompt
- 敏感词风控
- 输出标准化json格式
-
网页 (Memory)
- 多轮对话
- 控制记忆上限(按轮数、按token[全量, 摘要……])
-
外部数据 (Indexes)
- 汽车博文生成,需要参考车型各类参数(pdf,md, txt……)
-
任务拆分 (Chain)
- 汽车博文3段式生成
- 根据brief =》开头
- 根据brief、开头 =》 中间
- 根据开头、中间 =》结尾
-
日志(Callbacks)
-
……
工具
目前开源工具包括以下几种:llama_index、langchain、semantic-kernel等。

婚姻及结婚
婚姻是以感情为基础的平等契约,结婚是恋爱达到一定阶段后需要法律及世俗认可的一个过程。
我可以理解没有感情的婚姻,但我不支持。(从这点看,我可能也是一个理想主义者)
结婚是两个人之间的事,尽量避免变成两个家庭之间的博弈,如果双方父辈有分歧,情侣应该统一战线推动分歧的解决。

如果一定把人划分为不同的阶级,只有统治阶级和被统治阶级
人性决定了理想国不会存在
所谓政体、制度亦不过是统治阶级与被统治阶级博弈的结果
被统治阶级注定要被剥削
和动物世界的弱肉强食没什么本质区别